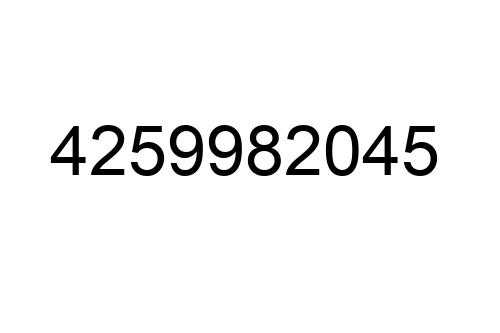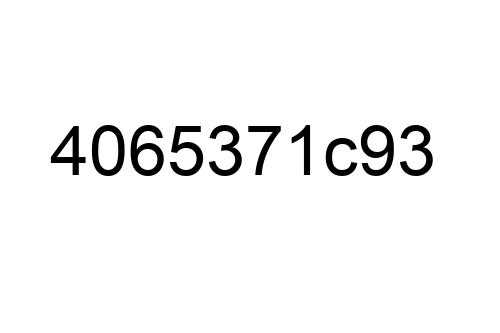Curious about how those random numbers in your favorite games or statistical analyses are generated? In this article, I’ll unravel the mystery behind Random Number Generators (RNGs) using the power of data insights. As an expert in the field, I’ll guide you through the fascinating world of RNGs, shedding light on their inner workings and dispelling common misconceptions.
Understanding RNGs is crucial not only for gamers and statisticians but also for anyone interested in the reliability of random processes in various applications. Join me as we delve into the algorithms, statistical properties, and practical implications of RNGs, demystifying these seemingly arbitrary numbers with a data-driven approach.
Get ready to uncover the secrets behind RNGs and gain a deeper appreciation for the role they play in shaping our digital experiences.
Understanding Random Number Generators (RNGs)
Exploring Random Number Generators (RNGs) reveals their crucial role in various applications. RNGs are algorithms generating sequences of numbers that lack any discernible pattern. They play a vital role in ensuring randomness in fields like gaming and statistical analysis. Delving deeper into the statistical properties and practical implications of RNGs enhances our grasp of their significance in shaping digital experiences.
Importance of RNGs in Data Analysis
Random Number Generators (RNGs) hold significant importance in data analysis for various applications. Let’s delve into how RNGs play a crucial role in statistical analysis and the benefits they offer in data modeling.
Applications of RNGs in Statistical Analysis
In statistical analysis, RNGs are fundamental in generating random data points for simulations, hypothesis testing, and creating random samples. By ensuring the randomness of the generated numbers, RNGs contribute to the accuracy and reliability of statistical analyses.
Researchers and data analysts rely on RNGs to imitate real-world scenarios and draw meaningful insights from data without bias.
Benefits of Using RNGs in Data Modeling

In data modeling, RNGs provide a basis for generating synthetic data sets that mimic real-world distributions. This enables data scientists to test and validate their models effectively. RNGs facilitate the creation of diverse scenarios, aiding in robustness testing and model validation.
By utilizing RNGs in data modeling, analysts can enhance the predictive power of their models and make informed decisions based on reliable data simulations.
Challenges and Limitations of RNGs in Data Science
Exploring the challenges and limitations of Random Number Generators (RNGs) in the realm of data science is crucial for understanding their impact on statistical analyses and modeling.
- Seed Sensitivity: RNGs are highly sensitive to their initial input, known as the seed. Small changes in the seed value can lead to significantly different sequences of random numbers, affecting the reproducibility of simulations and analyses.
- Periodicity: Some RNG algorithms exhibit periodic behavior, where the sequence of numbers repeats after a certain number of iterations. This periodicity can introduce bias and affect the randomness of generated data, compromising the accuracy of statistical results.
- Quality of Randomness: Assessing the quality of randomness produced by RNGs is essential. Lower-quality RNGs may fail statistical tests for randomness, leading to skewed results and erroneous conclusions in data analysis.
- Speed vs. Quality Trade-off: High-quality RNG algorithms often require more computational resources and time to generate random numbers accurately. Balancing the need for speed in large-scale simulations with the demand for high-quality random sequences is a common challenge in data science applications.
- Predictability Concerns: In certain cases, RNGs that exhibit predictability tendencies can be exploited by malicious actors to predict future random numbers, compromising the security and integrity of data-driven systems.
By understanding these challenges and limitations, data scientists can make informed decisions when selecting and implementing RNGs in statistical analyses and modeling, ensuring the reliability and accuracy of their data-driven insights.
Best Practices for Utilizing RNGs in Data-Driven Experiments
In data-driven experiments, utilizing Random Number Generators (RNGs) effectively is paramount to ensure the accuracy and reliability of statistical analyses. Here are some best practices to consider:
- Seed Initialization: Always initialize the RNG with a unique seed value to start the random number generation process. A good practice is to use a seed that incorporates various factors like timestamps or unique identifiers to enhance randomness.
- Quality Assessment: Regularly assess the quality of the RNG being used. Check for statistical properties like uniform distribution, independence, and unpredictability to validate the randomness of the generated numbers.
- Algorithm Selection: Choose RNG algorithms carefully based on your specific requirements. Consider factors like speed, period length, and statistical quality to determine the most suitable algorithm for your data-driven experiments.
- Replicability Testing: Verify the replicability of your results by rerunning experiments with the same seed. This ensures that the outcomes remain consistent and reproducible, crucial for validating the robustness of your analyses.
- Security Measures: Implement security measures to protect against potential exploitation of RNG vulnerabilities. Utilize cryptographic RNGs for sensitive applications to prevent predictability and safeguard data integrity.
By adhering to these best practices, I can optimize the utilization of RNGs in data-driven experiments, enhancing the accuracy and reliability of statistical analyses while mitigating potential risks associated with random number generation.